Разберем настройки этой записи.
Название: я предлагаю руководствоваться форматом «адрес сайта без https — страница — подстраница», в нашем случае, название будет выглядеть как «cbr.ru daily».
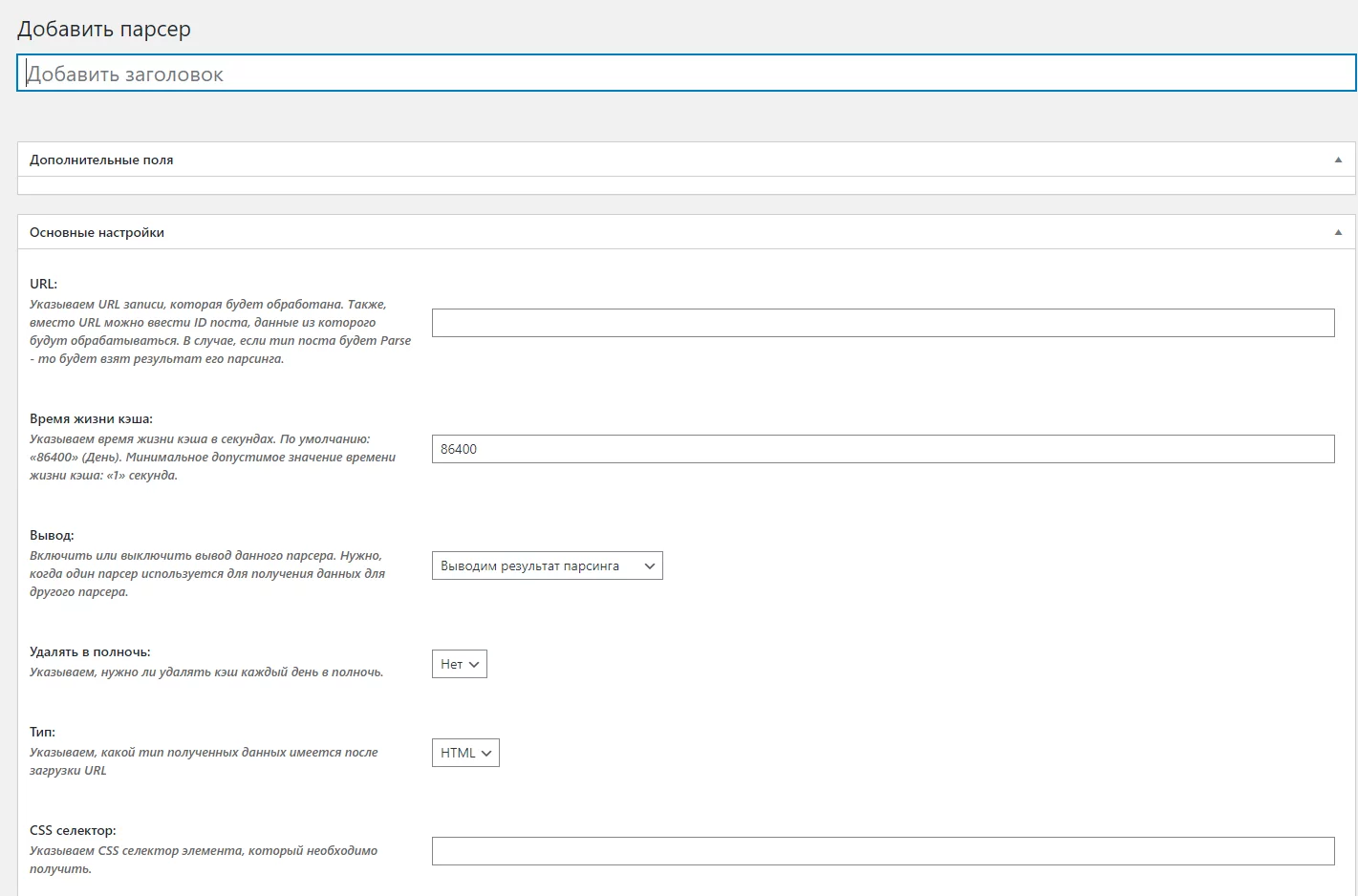
URL: очевидно, что он будет выглядеть как «https://www.cbr-xml-daily.ru/daily_utf8.xml»
Время жизни кэша: надо понимать, что курс валют обновляется каждый день. Соответственно, задавать что-то другое в данном пункте, отличное от значения по умолчанию, не имеет смысла. Минимальное значение: 1, что соответствует 1 секунде. Меньше ставить нельзя.
Удалять в полночь: очень важный пункт для нашей задачи. Поскольку курс валют обновляется каждый день, задать время жизни ему так, чтобы он был новый каждое утро — невозможно. Но данный пункт позволяет проверять, наступил ли новый день, и если да — то удалять старый кэш. Тем самым, ставим этот параметр в значение «Да».
Вывод: поскольку мы очень хотим посмотреть результат сразу — оставим этот параметр в значении «Выводим».
Тип: устанавливаем в XML, потому что на входе именно такие данные мы и имеем.
CSS селектор: не трогаем.
Удалять теги: не трогаем.